Testinnsikt 2026
Velkommen til SOCOs plattform for dypere analyser av temaer innen testfaget i Norge!
Årets tema er KI og hvordan det blir brukt innen testfaget i dag. Vi ser både på bruk av KI til testing og testing av KI-genererte løsninger.


Endring siden 2024
Hypotese: Bruken av KI har økt på alle områder siden forrige undersøkelse i 2024.
Se mer

Noen av spørsmålene i årets undersøkelse ble også stilt i undersøkelsen for to år siden.
Ikke overraskende har bruken av KI økt på samtlige områder.
For to år siden hadde bruken av KI som sparringpartner, chatbot og søkemotor allerede nådd 50 %. Nå i år bruker hele 86 % KI til slike formål – selvsagt godt hjulpet av at KI-resultater nå er en del av standard Google-søk.
For to år siden hadde omtrent en fjerdedel av respondentene erfaring med å integrere KI i løsningene som ble utviklet. Dette har økt til rett over 50 % i år.
Den største relative økningen i KI-bruk har kommet innenfor testfaget, der 57 % av respondentene nå benytter KI-hjelp til forskjellig testarbeid, alt fra å skrive enhetstester til å lage utkast til testplaner og strategier. I tråd med utviklingen innen KI, er det rimelig å anta at nyere modeller og verktøy er mer praktisk nyttige enn de som var tilgjengelige for to år siden.
Er det forskjeller i utbredelsen av KI mellom offentlig og privat sektor?
Ja, det er det – spesielt når det gjelder å ta i bruk KI i produktene som lages. Andelen som har implementert løsninger med KI integrert har økt betydelig begge steder, selv om privat sektor fortsatt ligger et godt hestehode foran.
Når det gjelder bruk av KI i daglig arbeid ser det derimot ut til at det har skjedd større endringer i offentlig sektor. For to år siden var bruken i privat sektor vesentlig høyere enn i offentlig sektor. Nyeste undersøkelse viser at forskjellen nesten helt utjevnet og nesten 9 av 10 respondenter får hjelp av KI til å løse hverdagens små og store problemer – uavhengig av sektor.
Se mindre


Effekt av KI-generert kode
Totalt har ca. 50 % av respondentene vært med å teste løsninger der KI har generert deler av koden. Hvilken effekt har utviklernes bruk av KI-verktøy på hverdagen til testere?
Se mer
Totalt mener 30 % at den opplevde kvaliteten på den KI-genererte koden er dårligere enn manuelt skrevet kode. Like mange mener det ikke gjør noen forskjell på kvaliteten, mens knapt hver fjerde opplever at den KI-genererte koden holder høyere kvalitet enn det de er vant med fra før.
Hvordan påvirkes testprosessen av KI-generert kode? En tredjedel mener at det ikke utgjør noen forskjell – jobben er den samme uansett. Én av fire opplever at testprosessen endres, for eksempel åpnes det for at tiden kan brukes annerledes i form av mer utforskende testing.
Alt i alt ser det ut til at en større andel opplever positive effekter enn de som opplever negative effekter.
Se mindre

Test av KI-løsninger
En fjerdedel av respondentene har vært med å teste produkter der KI er en integrert del av løsningen. Hvilke utfordringer byr det på?
Se mer
De aller fleste løsninger tar i bruk innkjøpt hyllevare som KI-komponent, for eksempel bruk av API-er fra OpenAI, Google eller Microsoft. Vi ser likevel at hele 15 % er helt egenutviklede løsninger, så det kan hende vi klarer å unngå 100 % amerikansk hegemoni på feltet.
Å teste KI er fortsatt nytt for de fleste, samtidig som modellene er i rivende utvikling, noe som ikke overraskende fører med seg en del utfordringer. Det ser fra tallene ut til at det er relativt sett større problemer med KI-spesifikke utfordringer enn testfaglige. En del synes det er krevende å lage testtilfeller og testdata, likevel er det mange flere som har problemer med utfallet av KI-modellene når testene faktisk kjøres.
Se mindre
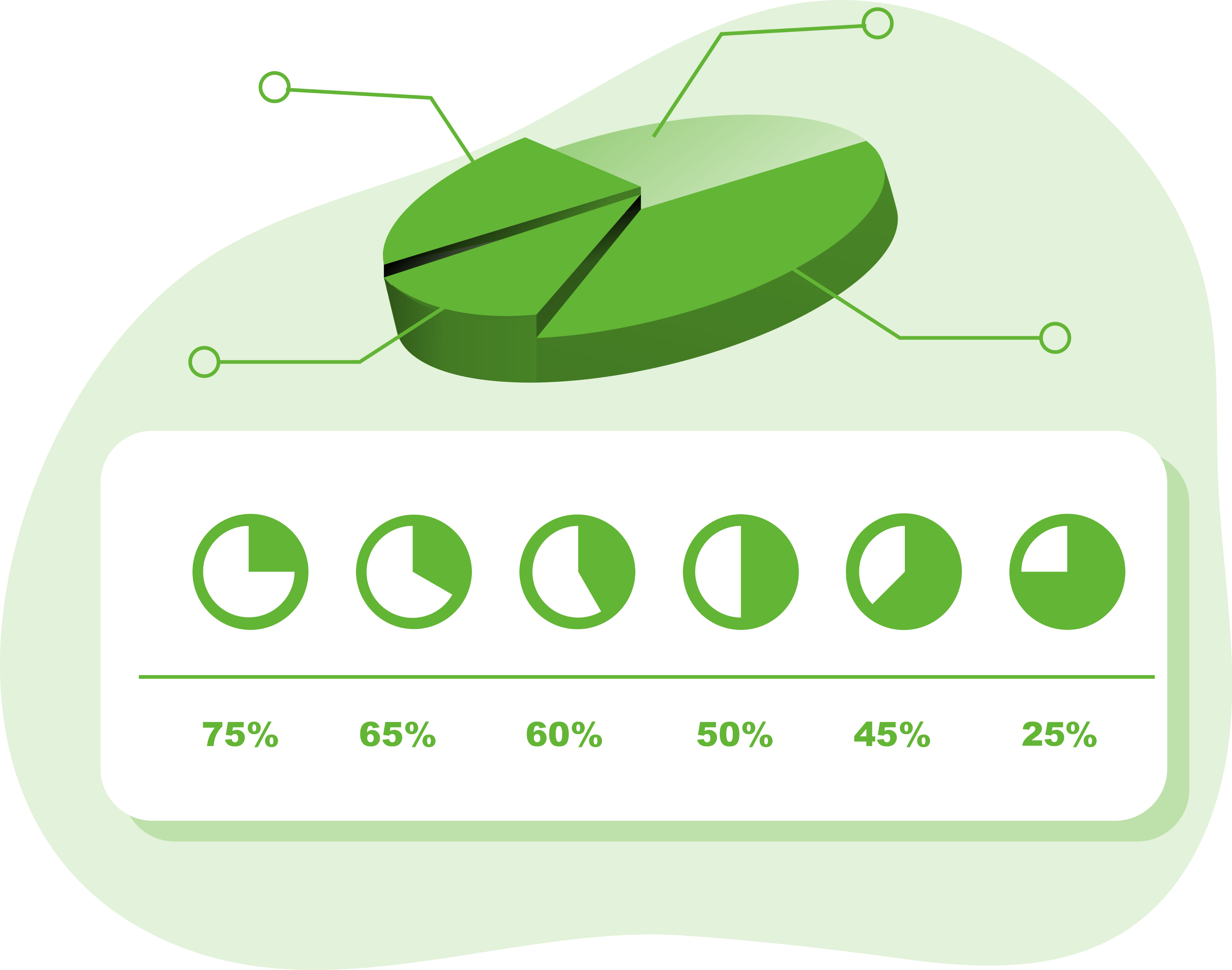
Bruk av KI til testarbeid
Seks av ti har brukt KI til å planlegge og/eller utføre testing
Se mer
De fleste stiller seg relativt nøytrale til det som KI produserer – en sunn skepsis kanskje? Kun 12 % har lav eller svært lav tillit, mens nesten 30 % har høy eller svært høy tillit.
Interessant nok er det en høyere andel som opplever å ha stor nytteverdi av KI i test, enn andelen som har høy tillit. Det kan kanskje tyde på at man bruker KI, drysser en klype salt over, og tilpasser til eget formål.
Undersøkelsen viser at det er bruk av KI-verktøy over et bredt spekter av områder. Grafen viser hvor stor andel av de som bruker KI til testarbeid som har brukt det på respektive områder. Lavest bruk finner vi på implementasjonsnivå i form av enhets- og integrasjonstester, og høyest som sparringpartner og til å foreslå testtilfeller. Dette virker naturlig, da styrken til dagens språkmodeller ligger i å generere tekst, og svare utfyllende på spørsmål. I tillegg har erfaringsmessing en betydelig andel av respondentene roller som ikke er rent tekniske.
Se ellers seksjonen med dybdeintervjuer for mer diskusjon rundt hvordan KI kan brukes i testarbeidet.
Se mindre

Dybdeintervjuer
I år har vi i tillegg til spørreundersøkelsen utført fem dybdeintervjuer med folk som benytter KI på ulike måter, fra rent testarbeid, via vanlig utvikling til mer industriell bruk. Ettersom bruken er såpass forskjellig, er det ikke så enkelt å dra klare konklusjoner på tvers – så innsikten gir et mer illustrerende bilde av hvordan KI brukes i dag, hvilke utfordringer som finnes og hvordan de håndteres. Seksjonene under er relevante innsikter for et gitt tema – hentet på tvers av intervjuene.
Se mer
Tillit og sikkerhet
Intervjuene viser at tillit til KI i stor grad er betinget av hvordan sikkerhet og personvern håndteres. Selv i organisasjoner som bruker KI aktivt i daglig drift, er det liten vilje til å overlate beslutninger fullt og helt til modellene.
Et tydelig eksempel kommer fra et produkt der generativ KI brukes til å analysere henvendelser fra publikum og foreslå mulige svar. Her er det et absolutt krav at alle svar kvalitetssikres av en kundebehandler før de sendes ut. KI får foreslå formuleringer, men det er mennesket som har det endelige ansvaret. Dette er et bevisst valg for å redusere risiko for feil, uheldige formuleringer eller brudd på regelverk.
Flere intervjuobjekter beskriver også hvordan GDPR og personvern har styrt tekniske valg. Ofte foretrekkes lokale modeller framfor skytjenester der det er praktisk mulig. Det er også bevisst bruk av anonymisering, maskering og vasking av data. Det utvises også forsiktighet med å bruke KI-genererte data rett i produksjon, men heller som støttesystem i bakkant.
Disse eksemplene viser at lav tillit til KI ikke nødvendigvis fører til lav bruk, men til strengere rammer, tydeligere ansvar og økt fokus på kontroll.


Hvordan brukes KI til testarbeid?
Intervjuene viser at KI først og fremst brukes der den gir støtte til menneskelig forståelse og analyse, snarere enn full automatisering av testarbeid.
Flere beskriver hvordan KI brukes som sparringspartner i testdesign. I ett intervju ble det beskrevet hvordan KI brukes til å analysere API-strukturer og automatisk generere forslag til testscenarier, som deretter vurderes og justeres av testeren før de tas i bruk.
Et annet eksempel er bruk av KI til å analysere store mengder dokumentasjon og kode for raskt å forstå systemets oppbygning og potensielle risikoområder. Dette gjør det mulig for testere å komme raskere i gang i komplekse prosjekter.
Et par av prosjektene hadde også tatt i bruk agentisk KI i utviklingsprosessen, både til automatisk kodegjennomgang, integrasjonstesting og sikkerhetstesting. Men også disse hadde manuelle godkjenningssteg i tillegg.
Felles for disse eksemplene er at KI fungerer som et støtteverktøy som forsterker testfaglig arbeid, ikke som en erstatning for det.
Det er gjennomgående at mange av prosjektene bærer preg av å være i tidlig fase, med prototyping og utforsking. Det er i liten grad formaliserte testprosesser på plass, og teamene er små – gjerne uten dedikerte testressurser.
Testing av KI
Når KI er en integrert del av løsningen, endres testarbeidet betydelig. Intervjuene bekrefter at tradisjonelle testmetoder ikke er tilstrekkelige alene.
Et tydelig eksempel kommer fra et miljø som jobber med avanserte modeller for sanntidsanalyse. Her beskrives det hvordan samme input kan gi ulike resultater avhengig av kontekst og data, og hvordan dette gjør faste testtilfeller mindre relevante. I stedet brukes data fra produksjon til verifikasjonstesting.
Andre strategier er å ha kjente resultater fra tidligere kjøringer, sammenligne med disse og vurdere hvor stort avvik det er forventet å være med den nye modellen.
Streng parameterkontroll bidrar til at modellene utviser mindre kreativitet, noe som gir mer forutsigbare resultater.
I en del tilfeller er det også mulig å be modellen om å forklare steg for steg hvordan den kom fram til resultatet. Det kan gjøre det enklere å ettergå prosessen og bygge tillit, eventuelt avdekke logiske brister i resonneringen.
Prosjektenes eksperimentelle natur og lite formaliserte prosesser gjør også at testing ikke er en avsluttende fase. Systemene overvåkes tett i produksjon, og avvik fanges opp gjennom driftssignaler og manuell vurdering. Testarbeidet fortsetter dermed som en del av driften.
Disse eksemplene illustrerer hvordan KI endrer testrollen. Testeren blir i større grad ansvarlig for å forstå systemets oppførsel over tid, og for å vurdere risiko og konsekvenser, fremfor å kun verifisere forhåndsdefinerte krav.


Testdata viktigere enn testtilfeller
Intervjuene indikerer at kvaliteten på testdata er avgjørende for kvaliteten på KI-løsninger, og at tradisjonelle testtilfeller alene ikke er tilstrekkelige. Dette gjelder spesielt der man utvikler egne KI-modeller med maskinlæring.
I ett intervju ble det uttrykt klart at syntetiske testdata kan være direkte misvisende og «farlige» i enkelte domener. I stedet brukes store mengder produksjonsnær data for å sikre at modellene testes mot reelle mønstre og avvik. Testingen fokuserer dermed mer på representativitet i datagrunnlaget enn på full dekning av forhåndsdefinerte testscenarier.
Ett prosjekt har også brukt en del ressurser på å utvikle domenespesifikke fysikksimulatorer som brukes til å verifisere modellene. For industrielle prosesser kan det være en god tilnærming.
I et annet prosjekt er det utstrakt bruk av syntetiske testdata, så behovene er fortsatt forskjellige. For ganske forutsigbare domener med transaksjoner, persondata og andre strukturerte data kan fortsatt syntetiske testdata være et godt valg. For andre applikasjoner som involverer mer ustrukturerte signaler, tolking av lyd- og videostrømmer og generell maskinlæring vil det være svært krevende å lage syntetiske data som dekker virkeligheten godt nok.
Fart og rot
KI-assistert koding kan gi økt tempo i utviklingen, noe enkelte av intervjuene også indikerer. Samtidig beskrives tydelige utfordringer knyttet til kvalitet og vedlikehold.
Et intervju trekker frem hvordan KI kan generere store mengder kode raskt, men med betydelig duplisering og manglende struktur. Det som skal være en liten justering fører til endringer i store deler av kodebasen, noe som gjør det uoversiktlig og vanskelig å forstå hva som er reelle endringer, og hva som bare er kosmetisk.
Eksempler som nevnes er også at den genererte koden er for generell, for eksempel at den ikke tilpasser godt nok til domene-spesifikke utfordringer. Generert kode kan også fungere bra i typiske tilfeller, men feile på spesialtilfeller. En respondent beskriver at KI har en tendens til å fylle ut en dårlig spesifikasjon med antagelser, noe som i enkelte tilfeller førte til kode som tilsynelatende gjorde noe fornuftig.
For å avdekke denne typen feil er det fortsatt svært viktig med god domenekunnskap, gode krav og presise kontrakter. Ett intervju påpeker også at de har bedre erfaring med å lage gode spesifikasjoner som KI lager kode på bakgrunn av, heller enn å be om kode direkte. Iterasjon på spesifikasjonen kan gi bedre resultat over tid. Samtidig medfører dette at koden re-genereres hver gang spesifikasjonen endres. Det gjør en tradisjonell flyt med versjonskontroll av koden utfordrende, ettersom det kan være store endringer, spesielt dersom man har oppgradert språkmodellen. Dette gjør gode tester svært viktig.
Dette har ført til at flere miljøer har skjerpet kravene til kodegjennomgang og regresjonstesting. KI-generert kode behandles som et utkast som må gjennom samme – eller strengere – kvalitetskontroller som menneskeskrevet kode. Ansvar for kvalitet ligger fortsatt hos utvikler og testteam, ikke hos verktøyet.

Se mindre
Oppsummering
Ikke overraskende har bruken av KI økt signifikant siden forrige undersøkelse for to år siden. Dette gjelder både generell bruk, integrasjon i utviklede løsninger og bruk som testverktøy.
Det prøves og feiles en del, mange opplever utfordringer og er kanskje ikke sikre på hvordan man best skal angripe problemet. Dybdeintervjuene gir inntrykk av at det er mye prototyping og utforsking på gang, både med tanke på produktutvikling og testing. Det er helt naturlig da KI-verktøyene også er i rivende utvikling fortsatt. Det som er sant i dag, gjelder ikke nødvendigvis om tre måneder.
Samtidig ser vi også eksempler på konkrete bruksområder der KI gir muligheter som ikke var der tidligere.
Det er en del skepsis til det som kommer ut av KI-modellene, både med tanke på korrekthet, men også bruken av data som gis til modellene. Dette håndteres med forsterkede kontrollmekanismer, menneskelig validering og forsiktighet med å eksponere KI-data direkte i produksjon.

KI-verktøy brukes og fungerer foreløpig best som støtteverktøy for analyse, design av testtilfeller, strategi og sparringpartner. Det brukes også til implementasjon og kjøring av tester, men i mindre grad. Dette virker naturlig, da de fleste verktøy er gode på å generere tekst, ikke nødvendigvis korrekte tekniske og domenespesifikke detaljer.
Kritisk tenkning, test- og utviklingsfaglig kompetanse og domeneforståelse virker å være viktigere enn noen gang.
1) Gjennomsnittlig erfaring for de som aldri bruker KI er 19,6 år